LINKZOL ®官网|人工智能|高性能计算领域服务器设备及OEM定制品牌厂商
LINKZOL ®官网|人工智能|高性能计算领域服务器设备及OEM定制品牌厂商 |
 :400-630-7530 :400-630-7530
|
 :sales@linkzol.com :sales@linkzol.com |
- 产品信息查询 - |
|
LINKZOL ®官网|人工智能|高性能计算领域服务器设备及OEM定制品牌厂商 |
:400-630-7530
|
:sales@linkzol.com |
- 产品信息查询 - |
|
|
解决方案
|
|
|
机器学习大热—— 深度学习GPU工作站、服务器主机配置支持两颗Intel E5-2600v3/v4 ,支持4块或8块TITANX,GTX1080Ti或Tesla P40,K80等GPU卡
深度学习是近几年热度非常高的的计算应用方向,其目的在于建立,模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解析数据,依据其庞大的网络结构,参数等配合大数据,利用其学习能强等特点,对于图像,音频和文字处理等具有重大意义。
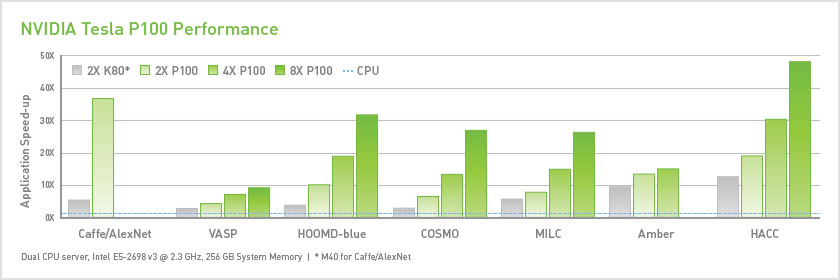
相较之于CPU来说GPU的计算效率是CPU计算效率的几十倍,GPU由大量的运算单元组成,并行计算能力远高于CPU,通常来说GPU拥有普通内存位宽更大,频率更高的专用显存,适合处理大规模数据的并行计算。LINKZOL?品牌产品都支持两颗Intel xeon E5-2600V4/V3系列处理器,支持4片和8片NVIDIA Tesla P100/P40/K80以及NVIDIA TITANX(PASCAL)和GTX 1080Ti等GPU卡的,单精度计算能最高达到12T FLOPS,对于深度学习来说无疑是最合适的计算应用。
和LZ-743GR-2G/Q都是目前深度学习应用在高校和科研院所最广泛的产品,两款产品都支持最新Intel xeon E5-2600V4处理器,分别可搭载4个和2个GPU计算卡,内存支持DDR4 2400/2133MHZ,最大容量支持2T,可最迟最大8个大容量磁盘,支持SATA,SSD,可选RAID卡部件,支持RAID0,1,5,10,50,6,60等RAID模式,最高传输效率达到1000MB/S,实现快速存储计算数据。
LINKZOLLZ-743GR-2G和LZ-748GT等GPU工作站支持7x24小时部件运行,所以部件均按照工业级环境设计,电源采用2000W白金和1200W金牌电源,通过80 Plus认证,能再180-240V,10.5A-8A,50-60MHZ电力范围正常工作,LZ-748GT采用冗余电源设计,允许其中一个电源宕掉的情况下保证设备的正常运行。同时LZ-748GT和LZ-743GR-2G都是采用4个高可靠的散热风扇,保证系统内部温度始终保持在合理范围。
硬盘采用企业级的HDD机械硬盘,和企业级的SSD固态硬盘。SSD主要安装系统,当然,也可以采用大容量的SSD做数据存储,一般情况下采用机械硬盘做数据的存储。
详情咨询:400-630-7530 E-MAIL :xiejin@linkzol.com
|
|